The KÉDDO story - Delivering a High Availability Private Cloud for Cost-Effectiveness
A prominent footwear brand KEDDO approached ITGLOBAL.COM’s Systems Integration department with a particularly challenging task. In doing so, KÉDDO found a partner that could implement a fault tolerant, high availability private cloud system hosted at two independent sites to safeguard business-critical services. We will show you how our team successfully implemented this cloud project for KÉDDO by leveraging integrated High-End solutions at no additional cost to the customer.About the Client
The story of KÉDDO began in 1990 in the United Kingdom with the inspiration to create footwear for young consumers who were searching for something fresh and distinctive. Fast forward a few years and the startup has grown into a global youth brand with a cult following. Today KÉDDO ranks among the top 20 world shoe brands with a brand presence in more than 80 countries around the globe.
When KÉDDO approached our Systems Integration team, the customer was relying on HP standby servers deployed in a Microsoft Hyper-V cluster. However, this approach was no longer meeting the client’s requirements for fault tolerance and performance, and the company sought a partner in the form of ITGLOBAL.COM to build a high availability private cloud that could deliver the fault tolerance and efficiency demanded by KÉDDO.
Our Expertise Maximizes Cost Competitiveness
Rising to KÉDDO’s challenge required in-depth development by highly competent specialists. The importance of high availability private cloud services to the client was only heightened by the pace of KÉDDO’s operating environment in the global fashion industry. Like any other industry sensitive to seasonal trends, footwear industry firms are unable to tolerate even minimal downtime. However, offering a standard solution, such as purchasing a backup system (subsequently referred to as BDR) was ultimately unsuitable for the client as the purchase cost of software like Veeam or Veritas, can often amount to tens of thousands of dollars.
In response to these requirements, the Systems Integration team at ITGLOBAL.COM offered a reliable and cost-effective proposal implementing the project through the organization of two IT sites:
- A primary datacenter with high performance and strict adherence to the fault tolerance requirements for the system.
- A secondary datacenter (DR) to run business-critical applications.
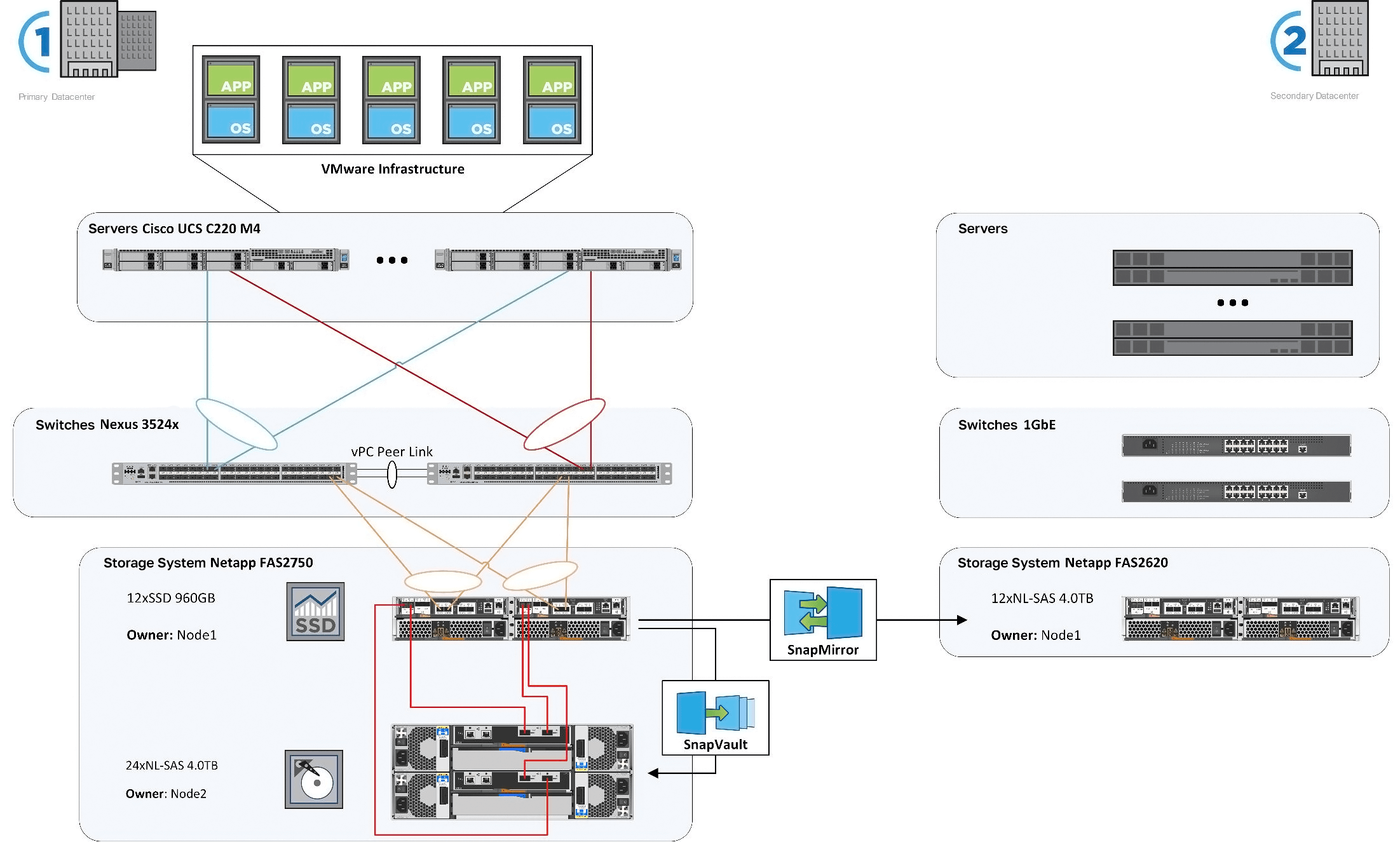
| 1 Primary Datacenter | 2 Secondary Datacenter |
|---|---|
| Cisco UCS C220 M4 servers | Servers |
| Nexus 3524x switches | 1 GbE switches |
| NetApp FAS2750 Data Storage System | NetApp FAS2620 Data Storage System |
Establishing a High Availability Private Cloud
To create a fault tolerant private cloud, our team employed:
- Cisco Nexus 3524 switches (two units).
- Cisco UCS 220 servers.
- Latest generation Hybrid Data Storage Systems (subsequently SAN) in the form of the NetApp FAS2750 (two units).
The architecture of our proposed solution allowed for the conditional segmentation of data relays and storage using the SnapMirror and SnapVault tools.
Switching
Network infrastructure was provided by two Cisco Nexus switches while the functionality of Virtual Port Channels (vPC) allowed for two devices to be connected to one stack. Thanks to vPC switches of this type, a high availability, fault-tolerant, but otherwise architecturally simple network access could be established. Moreover, each Nexus switch has its own independent control and management plane, with the customer able to aggregate the channels distributed between the two switches.
Data Storage
The data storage solution for the primary IT site is based around a NetApp FAS2750 data storage system. This SAN is deployed in a cluster configuration with two controllers, which are connected to each other through a cluster interconn—ector, and have dedicated 10GbE ports (two ports on each controller). System expansion and future proofing is further possible via the capability to scale the system up to 8 controllers. Each DSS controller comes with a 512Gb-sized NVMe M.2 card that can be used as L2 FlashCache, a read-cache at the controller-level that reduces latency for random read operations.
Our SAN works under the control of the NetApp Data ONTAP 9.2 OS which provides a universal repository that can both provide and block file access to information. The choice of the NetApp data storage system was made not only on the basis of performance and cost-effectiveness, but also on available software functionality as the ONTAP 9.2 Premium OS includes tools such as SnapMirror and SnapVault.
SnapVault
By selecting a version of ONTAP Premium with the built-in SnapVault feature, our team provided KÉDDO with the ability to create rapid backups on the basis of instantaneous imaging or “snapshots” at the virtual machine level. Additionally, the bundling of SnapVault plus the Virtual Storage Console for VMware vSphere, SnapManager for MS SQL and SnapManager for Exchange allowed the system to quickly recover data at a given point in time without affecting productivity and provided a capability for granular recovery at the level of an individual file, mailbox or email.
SnapMirror
Another functionality provided by ONTAP Premium is SnapMirror, a tool for asynchronous data replication between two physical storage systems. Replication occurs on an IP network which constitutes a significant difference between it and competing replication solutions from other vendors that often prefer FC. SnapMirror for SVM allows the replication of all data and settings on the SAN right at the secondary datacenter (DR).
During the deployment phase of the BDR by the means of SAN, it was decided to use the Identity Discard mode for the SAN or NAS. In this VM mode, a NFS-vsphere is generated as a Datastore while separate iSCSI LUN are assigned for databases and logs.
Workflow Automation
Use of the Workflow Automation tool allows for the creation of task sets or bundles to automate ONTAP management processes, for example:
- Сonfiguring the creation of new permissions for file spheres and iGroup.
- Adding replicated volumes and new initiating hosts from the DR site.
- Increasing new LIF interfaces and much more (creating a Broadcast Domain, Failover Groups, Firewall Policies, Routes, DNS, etc).
Workflow Automation allows the achievement of a high level of process automation, to the extent that all necessary tasks executed immediately after a break in replication can be accomplished with literally one click of a mouse.
Testing the Solution
A failure of the main SAN was modeled as part of the load testing by ITGLOBAL.COM specialists with the result that all critical services were successfully launched at the backup secondary datacenter. Indeed, the only tasks remaining for the customer’s integration team were the reconfiguring of IP addresses and other settings that were not replicated under Identity Discard mode. These remaining tasks would be accomplished by means of the data available on the secondary SAN after the switchover.
The Identity Discard mode provides the further benefit of allowing the customer to check the reserve backup for the possibility of its recoverability, a functionality that is also of interest to customers requiring the ability to replicate LUNs to read data at a backup site.
Results
Given that the reliability of equipment offered on the market is overall very high (99.999% with aims to achieve 99.9999%), we saw a need to put much more emphasis on the software component of the implemented solution for customers. It is precisely this high level of integration of hardware with software applications without the use of a separate BDR that allowed us to ensure the completion of all client tasks within the framework of building a high-performance, fault tolerant private cloud.
By choosing to create High Availability Private Cloud through the use of NetApp and CISCO solutions within the FlexPod architecture, our Systems Integration team not only provided the high IT infrastructure fault tolerance and performance levels demanded by a dynamic global business, but they also achieved significant savings by foregoing a separate BDR, leveraging their expertise to implement a Disaster Recovery system by means of a SAN instead. All the work necessary for the establishment of the backup complex and migration of information systems from old equipment was accomplished in only 3 months without any downtime for the customer.