С NVIDIA H200 PCIe ситуация стала особенно неоднозначной. Речь идёт прежде всего о картах NVIDIA H200 NVL 141 GB PCIe Passive GPU, которые на рынке представлены как в оригинальном исполнении, так и в виде модифицированных OEM-вариантов. Но по сути это разные продукты, и разница проявляется не в первом запуске, а позже, когда инфраструктуру нужно поддерживать, обновлять, масштабировать и отвечать за SLA.
Анатомия двух вариантов: нативная NVIDIA H200 PCIe и адаптированный SXM-модуль в формате PCIe
Оригинальная NVIDIA H200 в форм-факторе PCIe представляет собой законченную серверную карту, где термодизайн, питание, механика и прошивки изначально рассчитаны на работу в стандартных PCIe-платформах. Вокруг таких ускорителей вендоры серверов формируют поддерживаемые конфигурации, а у заказчика появляется чёткое разделение ответственности между производителем GPU, платформой и интегратором.
Под «OEM-версией» H200 PCIe скрывается иной подход: SXM-модуль, предназначенный для HGX-систем, физически переносится на плату-переходник для установки в PCIe-слот. На базовом уровне используется тот же GPU, поэтому карты могут выглядеть эквивалентными по функциональности и производительности. Однако по мере эксплуатации начинают проявляться отличия, связанные с отсутствием официальной гарантии NVIDIA и инженерными компромиссами при охлаждении и питании. SXM-модули проектировались для работы в составе HGX-систем с централизованным охлаждением и теплопакетом до 700 Вт под типовой нагрузкой. Оригинальные PCIe-карты H200, в свою очередь, рассчитаны на 600 Вт и иной профиль теплоотвода в стандартных серверных платформах. При переносе SXM-модуля в PCIe-формат эти различия в термодизайне могут приводить к перегреву, троттлингу и снижению стабильности при длительных нагрузках.

Рис 1. — Плата-переходник c SXM на PCIe (Image credit: @I_Leak_VN on X)
Отдельное различие связано с программным стеком. Для оригинальных NVIDIA H200 NVL в PCIe-исполнении предусмотрена пятилетняя подписка NVIDIA AI Enterprise Software (NVAIE), что напрямую влияет на модель эксплуатации. В этом случае заказчик получает не только ускоритель, но и доступ к поддерживаемой корпоративной AI-платформе с формализованной поддержкой и обновлениями, что заметно снижает риски при построении и масштабировании production-инфраструктуры.
Ценность программного стека NVAIE
Если бы выбор H200 PCIe сводился только к «чистым» вычислениям, он действительно чаще упирался бы в поставку и цену. Однако в корпоративном AI ключевым отличием оригинальных карт становится включённая NVIDIA AI Enterprise. Это не просто лицензия, а поддерживаемый программный контур для промышленной эксплуатации, который сразу задаёт другой уровень предсказуемости и ответственности по сравнению с «голым» железом.
На практике здесь сталкиваются два подхода к инференсу. vLLM даёт максимальную гибкость, но требует зрелой команды: подбора окружений, совместимых драйверов и CUDA, настройки оптимизаций, мониторинга, обновлений и безопасности. Для команд, где AI-практика только формируется, это часто превращается в узкое место. NVIDIA NIM закрывает другую задачу: это поддерживаемые контейнеризованные микросервисы для инференса, оптимизированные под конкретные GPU. Их ценность не в формате доставки, а в скорости вывода сервиса в эксплуатацию и снижении операционных рисков за счёт фиксированных конфигураций, обновлений и воспроизводимости при масштабировании.
Дополняет эту архитектуру технология NVIDIA MIG (Multi-Instance GPU) — механизм аппаратного разделения одного физического ускорителя на несколько изолированных экземпляров. В случае с H200 один GPU может быть разбит до 7 независимых MIG-инстансов, каждый со своими вычислительными блоками, памятью и гарантированной изоляцией ресурсов.
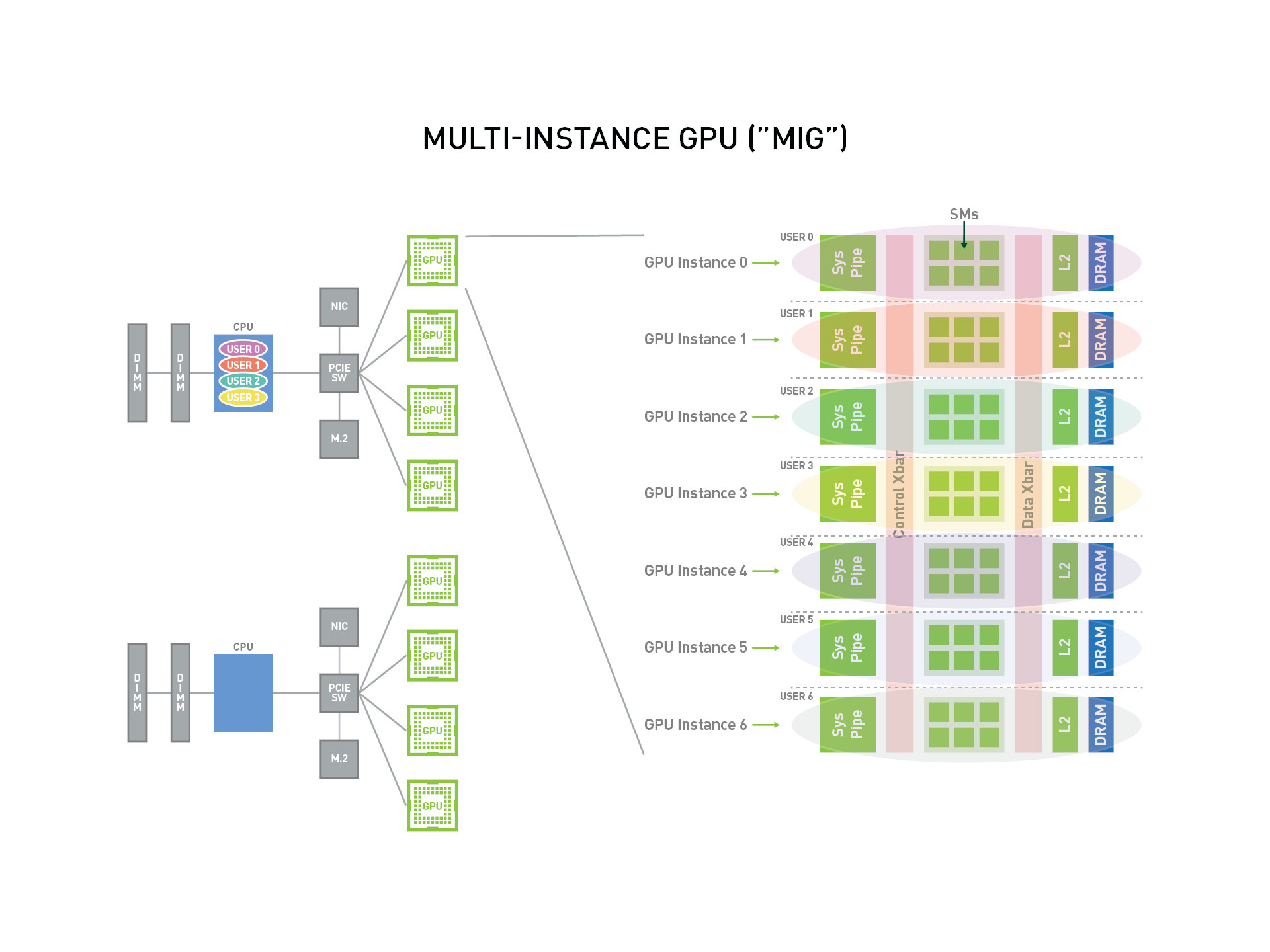
Рис. 2 — Обзор NVIDIA MIG
На практике это означает, что вместо одного крупного «монолитного» сервиса можно запустить несколько отдельных инференс-контуров. Например, разные небольшие модели до 8B параметров — такие как LLaMA 3.1-8B или Mistral-8B — размещаются в собственных MIG-partition и не конкурируют друг с другом за ресурсы. Нагрузка одной модели не влияет на стабильность соседней.
| Профиль MIG | Доля памяти | Доля SM | Аппаратные блоки | L2-кэш | Копирующие движки | Доступное число инстансов |
|---|---|---|---|---|---|---|
| MIG 1g.18gb | 1/8 | 1/7 | 1 NVDEC / 1 JPEG / 0 OFA | 1/8 | 1 | 7 |
| MIG 1g.18gb + media extensions | 1/8 | 1/7 | 1 NVDEC / 1 JPEG / 1 OFA | 1/8 | 1 | 1 (медиа-расширение доступно только для одного профиля 1g) |
| MIG 1g.35gb | 1/4 | 1/7 | 1 NVDEC / 1 JPEG / 0 OFA | 1/8 | 1 | 4 |
| MIG 2g.35gb | 2/8 | 2/7 | 2 NVDEC / 2 JPEG / 0 OFA | 2/8 | 2 | 3 |
| MIG 3g.71gb | 4/8 | 3/7 | 3 NVDEC / 3 JPEG / 0 OFA | 4/8 | 3 | 2 |
| MIG 4g.71gb | 4/8 | 4/7 | 4 NVDEC / 4 JPEG / 0 OFA | 4/8 | 4 | 1 |
| MIG 7g.141gb | Полный объём | 7/7 | 7 NVDEC / 7 JPEG / 1 OFA | Полный объём | 8 | 1 |
От пилота к промышленной эксплуатации
Благодаря тому, что в серверах ITPOD из серии AI/ML Computing используются только оригинальные PCIe карты от NVIDIA, ITGLOBAL.COM как облачный сервис-провадйер предлагает воспользоваться заказчикам всеми преимущества NVIDIA AI Enterprise Software. Заказчики получают максимальную производительность и утилизацию ресурсов, включая поддержку последних оптимизаций и технологий. В связке это даёт предсказуемый SLA, прозрачный аудит и минимизацию рисков при масштабировании корпоративного AI.


