

Современные приложения в области машинного обучения, интернета вещей, in-memory баз данных, а также торговые площадки, банковские системы и другие ресурсозависимые области использования ИТ предъявляют все возрастающие требования к скорости обработки информации.
Показатели задержки доступа к данным даже самых производительных all-flash-систем могут не устраивать потребителя и являться узким местом в процессах, на которых основана их бизнес-деятельность.
Компания NetApp плотно работает над созданием алгоритмов взаимодействия приложений с данными, которыми они оперируют. Одним из положительных результатов такой работы смело можно считать продукт NetApp MAX Data (Memory Accelerated Data), который был анонсирован 2 апреля 2019 года. MAX Data задействует Persistent Memory (PMEM) для достижения минимальных показателей задержки при обращении к данным.
Persistent Memory
Persistent Memory, или постоянная память, вобрала в себя лучшие технологические решения от DRAM (Dynamic Random Access Memory) и носителей с сохранением состояния после отключения энергопитания (HDD, SSD). Persistent Memory также называют NVRAM (Non-Volatile Random Access Memory) или NVDIMM, что указывает на наличие в PMEM решений от классической оперативной памяти, что и приближает ее по скорости и показателям задержки к DRAM, но в то же время позволяет не терять данные при выключении.
Начало использования Persistent Memory было сопряжено с некоторыми трудностями. «Классические» приложения используют два уровня памяти во время своего жизненного цикла: оперативную память и более медленные накопители «постоянной» информации. Уровень PMEM лежит где-то посередине, поэтому «из коробки» приложение не начнет нативно с ним взаимодействовать. Для реализации потенциала Persistent Memory существует две возможности: переписать приложение с поддержкой PMEM либо использовать некий слой абстракции, который будет самостоятельно взаимодействовать с постоянной памятью, позволяя приложениям даже не знать о ее существовании. NetApp пошел именно по второму пути.
Путь MAX Data
Как упоминалось выше, NetApp выбрал путь предоставления слоя абстракции для приложений для работы с постоянной памятью. Решение получило название MAX Data, в его основу легла технология MAX FS – файловая система с автоматическим управлением перемещением данных по уровнями хранения. Первый уровень хранения (memory tier) находится непосредственно на сервере и представляет собой Persistent Memory. Второй уровень находится, к примеру, на массиве NetApp (storage tier). Если максимально упростить, то MAX FS перемещает неиспользуемые данные из Persistent Memory (memory tier) на уровень хранения и наоборот.
Так как MAX FS (Memory Accelerated File System) является POSIX-совместимой файловой системой, то нам нет необходимости переписывать заново приложения. Мы просто используем его и за счет алгоритмов MAX Data получаем минимальные показатели задержки в работе с данными.
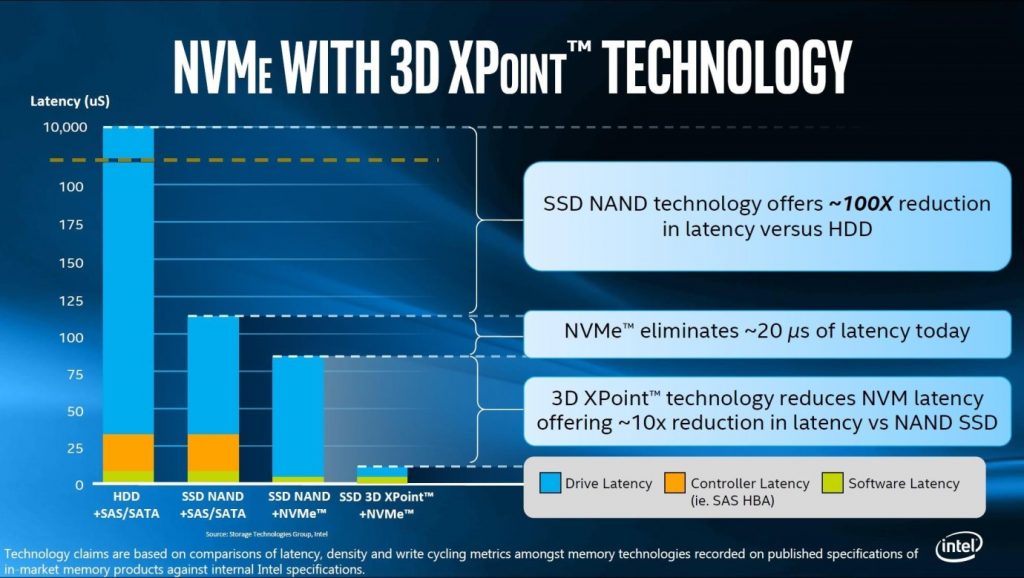
В первых ревизиях MAX Data использовались технологии DRAM и NVDIMM для реализации memory tier. Но DRAM не позволяет нам хранить состояние памяти после выключения, а NVDIMM имеет не самые лучшие показатели вместительности и требует специфичных материнских плат для установки.
NetApp вышла из ситуации, начав использовать Intel Optane DC Persistent Memory с микросхемами 3D XPOINT. Решение было официально представлено на Intel Data Center Tech Summit только летом 2018 года, но компания NetApp сразу увидела в нем потенциал для повышения скорости работы приложений при использовании совместно с Max Data.

Стоит отметить, что Max Data – это не решение для кеширования, которое просто копирует горячие данные в область более быстрой памяти. Max Data использует memory и storage tiers именно для перемещения данных для быстрого обращения к ним. Когда memory tier переполняется, то более холодная дата уходит на более медленный storage-уровень.
А это безопасно?
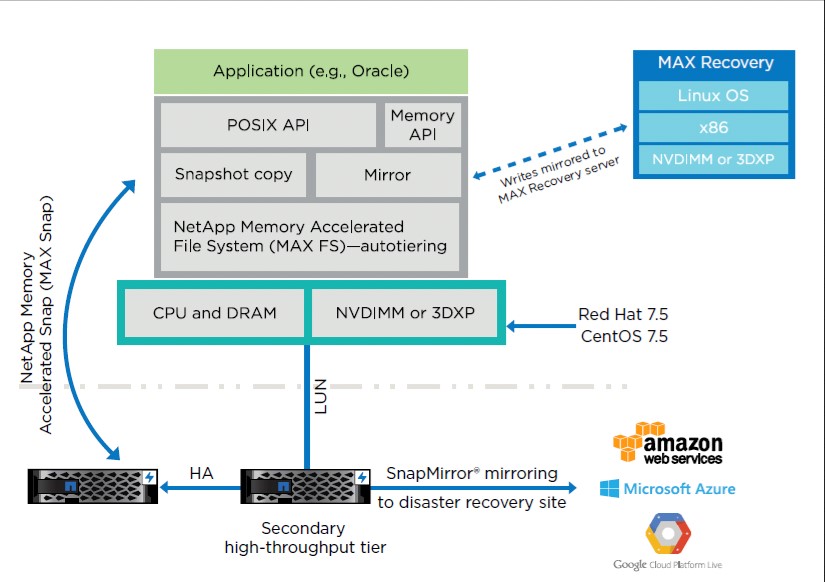
Абсолютно. Компания NetApp позаботилась о защите информации, создав решение Memory Accelerated Recovery (MAX Recovery), которое позволяет зеркалировать (memory-to-memory replication) Intel Optane DC на серверах и использовать все удобство снэпшотов NetApp для организации резервного копирования на NetApp All-Flash FAS. За счет использования ONTAP нам доступны все функции по обеспечению отказоустойчивость, дедупликации, восстановления после сбоя и другие.
Взгляд в будущее
У технологии Max Data и Persistent Memory хороший потенциал. Существующих скоростей и показателей задержки у «классических» носителей информации уже не хватает, а использовать везде in-memory-технологии не всегда разумно. Поэтому MAX Data стало универсальной палочкой-выручалочкой для приложений, где необходимы действительно околонулевые показатели задержки.
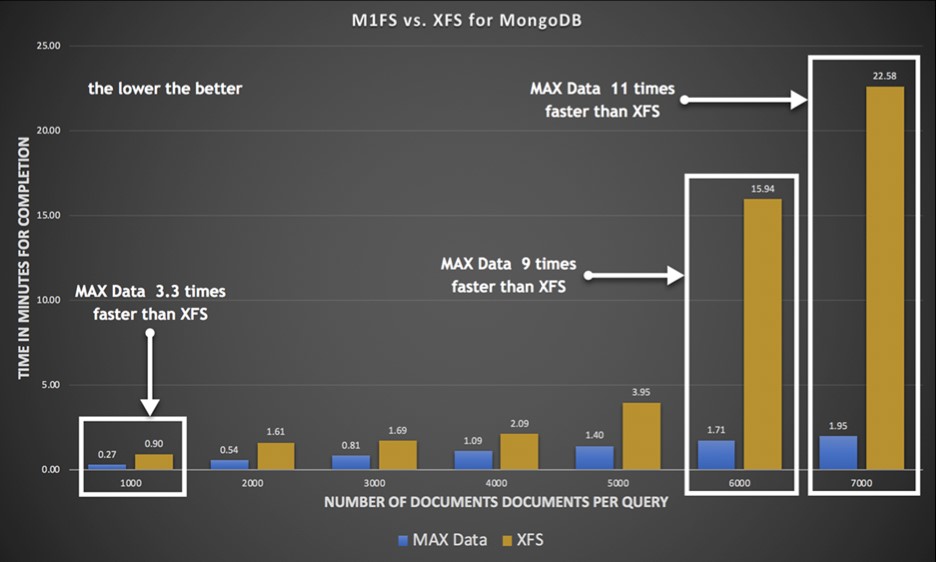
На NetApp Insight 2018 сравнивали MAX FS по скорости работы с XFS. Для этого использовали MongoDB. MAX FS при низких нагрузках показал производительность в 3,3 раза выше, а на более высоких нагрузках очередь обрабатывалась в 11 раз быстрее. Показатели задержки у 3D XPoint колеблется в районе 10 микросекунд, что в 10 раз меньше, чем у быстрой NAND SSD, что дает нам существенный прирост производительности любых приложений, работающих совместно с MAX Data.
Суммировав все вышеописанное, можно с уверенностью сказать: технологии для работы с Persistent Memory будут набирать все большую популярность и все больше компаний видят в ней высокий потенциал. Так, VMware в версии гипервизора vSphere 6.7 добавлена возможность использования постоянной памяти.
За счет качественного скачка производительности при использовании MAX Data можно сократить количество оборудования для получения необходимого time to value от приложений. Возможность использования MAX Data совместно с in-memory databases MongoDB, Redis, Cassandra и другими добавляет дополнительные преимущества при работе с машинным обучением, аналитическими данными и другими ресурсоемкими приложениями.


