Почему одного GPU недостаточно
DeepSeek 3.2 — модель с сотнями миллиардов параметров. Даже в квантованном виде она требует десятков гигабайт видеопамяти только для хранения весов. Добавьте сюда KV-cache для длинных контекстов, активационную память при обучении и промежуточные тензоры — и становится ясно, почему один ускоритель становится узким местом.

Работая в проде, инженеры сталкиваются с типичным набором проблем: низкая скорость генерации при высоких нагрузках, невозможность обслуживать длинные контексты без деградации производительности, неэффективное использование дорогостоящего железа и отсутствие понятного пути к горизонтальному масштабированию. Решение — грамотно выбранная стратегия параллелизации, а нередко и их комбинация.
Пять стратегий оптимизации: от простого к комплексному
| Стратегия | Требования к VRAM (на 1 GPU) | Меж-GPU трафик | Чувствительность к связи | Сложность настройки | Типичный сценарий |
|---|---|---|---|---|---|
| Data Parallelism (DP) | Высокие (полная копия модели) | Низкий (только градиенты) | Низкая | Низкая | Обучение/файн-тюнинг на огромных датасетах, когда модель влезает в 1 GPU |
| Tensor Parallelism (TP) | Низкие (вес делится на $N$ частей) | Очень высокий (внутри слоев) | Критическая (нужен NVLink) | Высокая | Инференс тяжелых моделей (DeepSeek), минимизация задержки (latency) |
| Pipeline Parallelism (PP) | Средние (группы слоев на GPU) | Средний (только активации) | Средняя (хватит 100GbE) | Высокая | Распределение гигантских моделей между разными серверами в кластере |
| ZeRO (DeepSpeed) | Минимальные (фрагментация всего) | Высокий | Высокая | Средняя | Обучение сверхкрупных моделей на ограниченном железе |
| 3D-Parallelism | Оптимальные (комбинированные) | Очень высокий | Высокая | Максимальная | Промышленные кластеры (H100/A100), high-end продакшн DeepSeek/GPT |
1. Data Parallelism — горизонтальное масштабирование через данные
Самый понятный и наименее требовательный к архитектуре подход. Каждый GPU получает полную копию модели и обрабатывает свой батч данных независимо. По завершении вычислений градиенты агрегируются через операцию AllReduce и синхронизируются между всеми устройствами.
Когда применять: модель целиком помещается в память одного GPU; нужно обработать большие объёмы данных — файн-тюнинг, переобучение, оценка на широком датасете; требуется максимально простое решение без сложной коммуникационной топологии.
Главное ограничение — полная копия модели на каждом устройстве. Для DeepSeek 3.2 это делает подход применимым лишь при квантовании до FP8 или INT4, когда модель умещается в 40–80 ГБ памяти.
2. Tensor Parallelism — разделение весов между ускорителями
Ключевая технология для работы с моделями, которые не помещаются в память одного GPU. Матричные операции — умножения весов внимания и MLP-слоёв — физически разделяются между устройствами. Каждый GPU хранит и обрабатывает только часть матрицы, а результаты объединяются через операции AllGather и AllReduce.
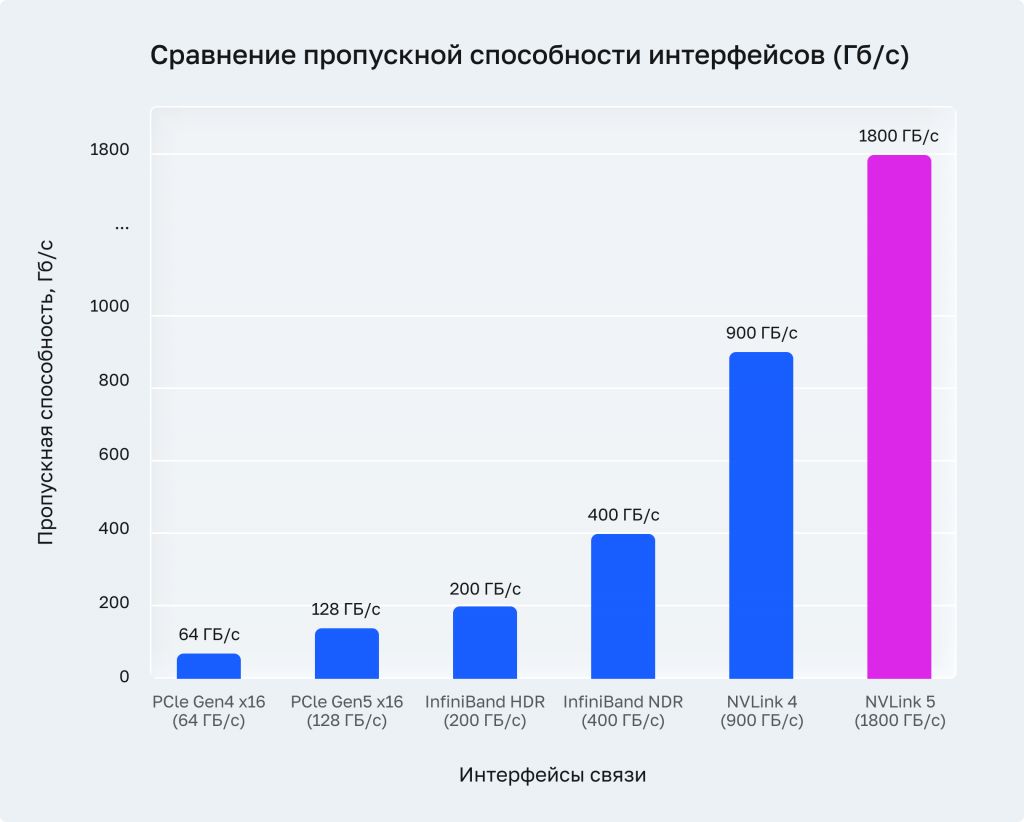
Именно этот метод обеспечивает линейный рост эффективной памяти: четыре GPU дают четырёхкратное увеличение доступной VRAM для хранения модели. Но здесь скрывается критическая зависимость от железа: Tensor Parallelism требует постоянного интенсивного обмена данными между GPU. На медленном соединении — например, через PCIe без NVLink — вся выгода от параллелизации съедается задержками коммуникации.
Практическое правило: Tensor Parallelism эффективен только при наличии высокоскоростного соединения между GPU. NVLink с пропускной способностью 600–1800 ГБ/с — обязательное условие. PCIe Gen4 x16 (64 ГБ/с) даёт приемлемый результат лишь для небольших степеней параллелизма (TP=2).
3. Pipeline Parallelism — вертикальное разделение по слоям
Вместо разделения внутри слоёв, Pipeline Parallelism делит модель по глубине: разные группы трансформерных блоков размещаются на разных GPU, образуя вычислительный конвейер. Первый GPU обрабатывает слои 1–16, второй — слои 17–32 и так далее.
Преимущество подхода — значительно меньший объём данных при соединении между GPU по сравнению с Tensor Parallelism: между устройствами передаются только активации (выходы слоёв), а не фрагменты весовых матриц. Это делает Pipeline Parallelism более терпимым к медленным соединениям и хорошо подходящим для распределения нагрузки между серверами в кластере.
Слабое место — пузыри в конвейере: пока первый GPU ждёт следующий батч, он простаивает. Алгоритмы вроде 1F1B (One Forward, One Backward) и интерливинга расписания существенно снижают этот простой, но полностью не устраняют.
4. 3D-параллелизм — промышленный стандарт для серьёзных нагрузок
На практике производственные системы уровня enterprise редко ограничиваются одним методом. 3D-параллелизм — это одновременное применение всех трёх стратегий с чётким распределением ролей по топологии кластера: Tensor Parallelism внутри одного сервера, между GPU, связанными NVLink (типичная конфигурация: TP=8 для сервера с 8×H100); Pipeline Parallelism между серверами в кластере, через высокоскоростную сеть (InfiniBand или 100+ GbE); Data Parallelism для масштабирования на дополнительные кластерные узлы при росте нагрузки.
Именно такая конфигурация позволяет запускать и обучать модели с сотнями миллиардов параметров — включая DeepSeek 3.2 — с приемлемой скоростью генерации. Меньшие степени каждого параллелизма можно варьировать в зависимости от размера модели, длины контекста и доступного железа.
5. Фреймворки, инструменты и обязательные оптимизации
Для инференса: vLLM — де-факто стандарт для прод-инференса. Технология PagedAttention позволяет динамически управлять KV-cache и обслуживать большое количество параллельных запросов без out-of-memory. TensorRT-LLM — максимальная оптимизация под архитектуру NVIDIA: kernel fusion, специализированные CUDA-ядра, поддержка FP8. Требует компиляции, но даёт наибольший throughput.
Для обучения и файн-тюнинга: DeepSpeed с ZeRO-оптимизатором (стадии 1–3) позволяет разносить состояния оптимизатора, градиенты и параметры по GPU, кардинально снижая требования к памяти каждого устройства.
Обязательные низкоуровневые оптимизации: Flash Attention v2/v3 ускоряет вычисление механизма внимания в 2–4 раза за счёт IO-aware алгоритма, снижает потребление памяти при длинных контекстах; квантование FP8/INT4/INT8 уменьшает размер модели в 2–4 раза с минимальной деградацией качества; Speculative Decoding использует малую draft-модель для предсказания следующих токенов, что ускоряет авторегрессивную генерацию.
Роль железа: почему архитектура сервера решает всё
Программные оптимизации работают в полную силу только при наличии правильной аппаратной основы. Коммуникационные задержки в распределённых системах — главное “бутылочное горлышко”, которое невозможно устранить на уровне кода.
NVLink и NVSwitch обеспечивают пропускную способность 600–900 ГБ/с — в 10–14 раз выше, чем PCIe Gen4. Без этой технологии Tensor Parallelism на степенях TP=4 и выше теряет большую часть теоретического прироста. Для DeepSeek 3.2 NVLink — не опция, а необходимость.
PCIe Gen5 x16 удваивает пропускную способность по сравнению с Gen4 и критически важна в конфигурациях, где NVLink отсутствует или используется Data/Pipeline Parallelism с интенсивным CPU-GPU обменом. Полное выделение линий PCIe на каждый GPU исключает конкуренцию за ресурсы шины.
При Pipeline Parallelism и масштабировании за пределы одного узла пропускная способность сети между серверами становится определяющей. 100 GbE — минимальный порог для нормальной работы; InfiniBand HDR/NDR (200–400 ГБ/с) — оптимальный выбор для высоконагруженных кластеров. Задержка порядка единиц микросекунд критична для синхронизации шагов в Pipeline Parallelism.
Инфраструктура под AI-нагрузки: что предлагают серверы ITPOD
Развернуть DeepSeek 3.2 с полноценной оптимизацией — значит обеспечить каждый программный слой соответствующей аппаратной поддержкой. Серверы ITPOD проектировались именно с учётом требований современных AI-нагрузок: поддержка GPU с технологией NVLink обеспечивает высокоскоростную коммуникацию между ускорителями — обязательное условие для эффективного Tensor Parallelism и 3D-параллелизма в целом; PCIe 4.0/5.0 с полным выделением линий на каждый GPU исключает узкие места на уровне шины; поддержка сетевых карт 100+ Gb Ethernet позволяет выстраивать мультисерверные кластеры для Pipeline Parallelism и масштабирования за пределы одного узла.
Когда аппаратная архитектура сервера соответствует требованиям выбранной стратегии параллелизации, теоретические преимущества distributed inference превращаются в измеримые производственные результаты: высокий throughput, стабильная работа с длинными контекстами и понятный путь к масштабированию при росте нагрузки.

