
В продолжение поста о распаковке Cisco UCS, приехавшей в наш Центр компетенции, мы расскажем о Cisco UCS Manager, с помощью которого производится настройка всей системы. Данную задачу мы выполнили в рамках подготовки к тестированию FlexPod (Cisco UCS + NetApp в режиме MetroCluster) для одного из наших заказчиков.
Отметим основные преимущества Cisco UCS, благодаря которым выбор пал именно на данную систему:
- Cisco UCS является унифицированной системой, а не разрозненной группой серверов с попыткой единого управления;
- наличие унифицированной фабрики, которая содержит встраиваемое управление, использование универсального транспорта, отсутствие уровня коммутации в шасси и на уровне гипервизора– Virtual Interface Card, простое каблирование;
- единая конвергентная фабрика на всю систему (единовременное управление до 320 серверами) в отличие от конкурентов – своя фабрика на каждое шасси (до 16 серверов);
- одна точка управления, быстрота конфигурирования при использовании политик и профилей, что дает минимизацию рисков при настройке, развертывании, тиражировании, обеспечивает высокую масштабируемость.
Традиционные блейд системы имеют следующие недостатки:
- каждый блейд-сервер – идеологически, с точки зрения управления такой же стоечный или башенный сервер, только в другом форм-факторе;
- каждый сервер – сложная система с большим числом компонентов и большим числом мощных средств управления;
- каждое шасси, каждый сервер, и в большинстве случаев каждый коммутатор должны настраиваться отдельно и чаще всего «вручную»;
- «зонтичные» «единые» системы управления существуют, но это в большинстве случаев просто набор ссылок на отдельные утилиты;
- интеграция «наверх» у этих систем возможна, но ограничивается «стандартными» простыми интерфейсами.
В отличие от конкурентов Cisco UCS имеет продуманную систему управления – UCS Manager. Данный продукт имеет следующие отличительные особенности:
- не требует отдельного сервера, СУБД, ОС и лицензий на них — он часть UCS;
- не требует инсталляции и настройки – просто включите систему и задайте IP-адрес;
- обладает встроенной отказоустойчивостью;
- имеет эффективные и простые средства резервного копирования конфигурации;
- обновляется несколькими «кликами»;
- делегирует весь свой функционал «наверх» через открытый XML API;
- стоит $0.00.
Сам Cisco UCS Manager располагается на обоих Fabric Interconnect, и, соответственно, все настройки, политики и т.п. хранятся также на них.
К одной паре Fabric Interconnect может подключено до 20 блейд-шасси. Управление каждым из шасси осуществляется из одной точки – UCS Manager. Это возможно благодаря тому, что Fabric Interconnect строится как распределенный коммутатор с участием Fabric Extender’ов . Каждое шасси имеет по два Fabric Extender, с возможностью подключения 4 либо 8 10GB линками каждый.
Начинаем с самого основного: подключения консольного провода и задания начального IP-адреса.
После чего запускаем браузер и соединяемся. (Понадобится java, т.к. по сути GUI UCS Manager’а реализовано на ней). На рисунках ниже представлен внешний вид программы, который появляется на экране после ввода логина и пароля и входа в UCS Manager.
Работу по настройке начинаем на вкладке «LAN». Надо отметить, что с настройки данной вкладки, а также вкладки «SAN» начинается настройка всей системы. Особенно актуально это в случае использования бездисковых серверов – как раз наш случай.
Здесь настраивается абсолютно все, что имеет отношение к сети: какие VLAN разрешены на том или ином Fabric Interconnect, какими портами соединены Fabric Interconnect между собой, какие порты в каком режиме работают и многое другое.
Также на этой вкладке настраиваются шаблоны для виртуальных сетевых интерфейсов: vNIC, которые в дальнейшем будут применяться в сервисных политиках, описанных выше. На каждый vNIC (которых к слову на хосте может быть до 512 при установке 2 плат Cisco UCS VIC) привязывается определенный VLAN, либо группа VLAN и «общение» физического хоста по сети идет именно через эти vNIC.
Организация такого количества vNIC возможна с помощью карты виртуального интерфейса VIC (Virtual Interface Card). В семействе блейд серверов Cisco UCS существует 2 вида VIC: 1240 и 1280.
Каждая из них имеет возможность поддержки до 256 vNIC или vHBA. Главное отличие в том, что 1240 является LOM модулем, а 1280 мезанинная карта, так же в пропускной способности.

1240 самостоятельно имеет возможность агрегации до 40 GB, с возможностью расширения до 80GB при использовании Expander Card.
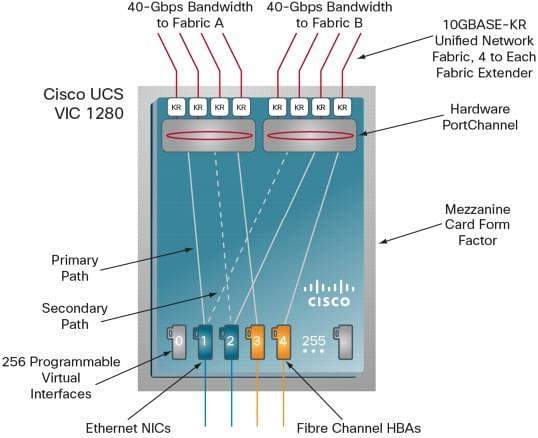
1280 изначально умеет пропускать через себя до 80GB.
VIC позволяют динамически назначать пропускную способность на каждый vNIC или vHBА, а так же поддерживают hardware failover.
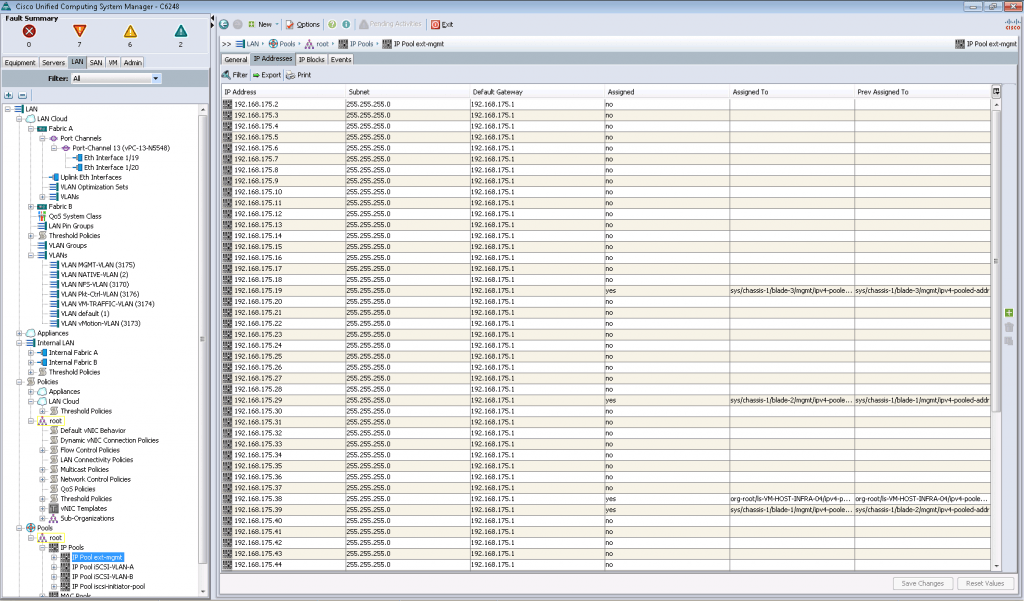
Ниже можно заметить несколько созданных пулов IP адресов, из которых эти самые адреса будут присваиваться сетевым интерфейсам в определенных VLAN (этакий аналог EBIPA у HP). Аналогично дело обстоит и с MAC адресами, которые берутся из MAC пулов.
В общем концепция простая: создаем VLAN(ы), настраиваем порты на Fabric Interconnect, настраиваем vNIC, выдаем этим vNIC MAC/IP адреса из пулов и загоняем в сервисную политику для дальнейшего использования.
Важное замечание: Как вы знаете существуют валидированные дизайны Cisco с крупными игроками рынка систем хранения данных, например, такой как FlexPod. Дизайн FlexPod включает серверное и сетевое оборудование – Cisco, а в роли СХД выступает NetApp. Зачем спросите вы там еще и сетевое оборудование? Дело все в том, что в версии 1.4 и 2.0 UCS Manager сам Fabric Interconnect не осуществлял FC зонирование. Для этого был необходим вышестоящий коммутатор (например, Cisco Nexus), подключенный к Fabric Interconnect через Uplink порты. В версии UCS Manager 2.1. появилась поддержка локальных зон, что дало возможно подключать Storage напрямую к Fabric Interconnect. Возможные дизайны можно посмотреть вот здесь. Но все-таки оставлять FlexPod без коммутатора не стоит, т.к. FlexPod является самостоятельным строительным блоком ЦОДа.
Перейдем к следующей вкладке: «SAN».
Здесь располагается все, что относится к сети передачи данных: iSCSI и FCoE. Концепция такая же, как и у сетевых адаптеров vNIC, но со своими отличиями: WWN, WWPN, IQN и т.п.

Переходим на вкладку «Equipment».

С помощью данного интерфейса можно увидеть информацию о нашей общей вычислительной инфраструктуре, которая была развернута для тестирования. Так, было задействовано одно шасси (Chassis 1) и четыре сервера-лезвия (Server1, Server2, Server3, Server4). Эту информацию можно получить из дерева в левой части (Equipment), либо в графическом виде (Physical Display).
Помимо количества шасси/серверов можно посмотреть информацию о вспомогательных компонентах (вентиляторы, блоки питания и т.п.), а также информацию об алертах разного типа. Общее количество алертов выводится в блоке «Fault Summary», отдельно информацию по каждому узлу можно посмотреть, кликнув по нему слева. Цветные рамки вокруг названий узлов слева помогают узнать, на каком узле есть алерты. Внимательные читатели заметят также небольшие пиктограммы и на графическом виде.
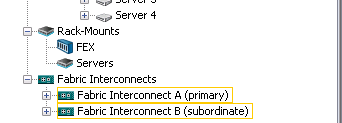
Наши Fabric Interconnect настроены на работу в failover режиме (при выходе из строя одного из агрегатов – его работу незамедлительно возьмет на себя другой). Информация об этом видна в самом низу дерева – обозначения primary и subordinate.
Далее переходим к вкладке «Servers».
Здесь находятся различные политики, шаблоны сервисных профилей и непосредственно сами сервисные профили. Например, мы можем создать несколько организаций, каждой из которых назначить свои политики выбора загрузочного устройства, доступа к определенным VLAN/VSAN и др.
На следующем рисунке показан пример настройки iSCSI загрузочного луна.
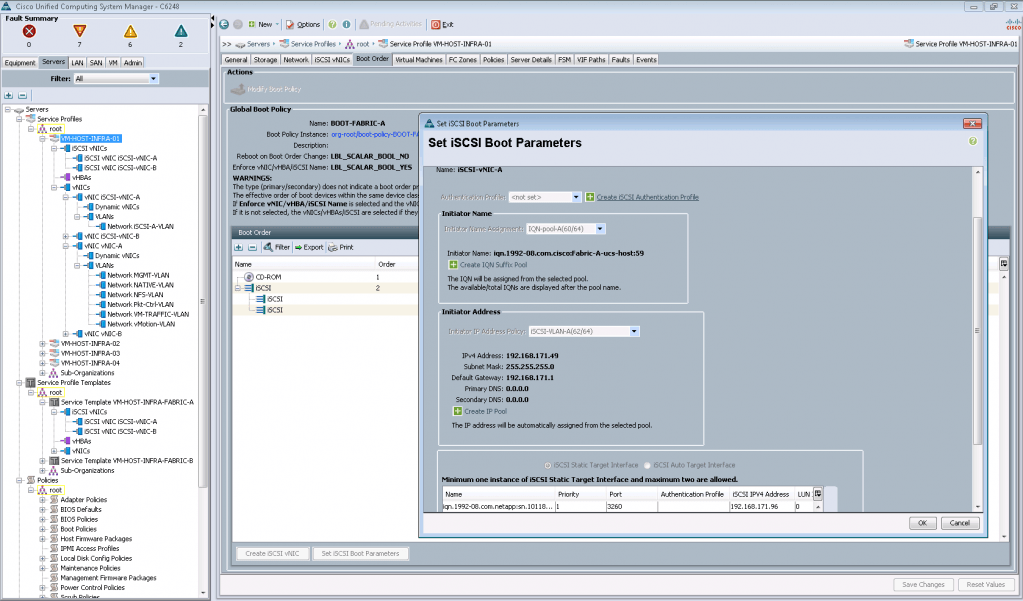
Глобальный смысл всего этого: предварительно настроив все политики и шаблоны, можно быстро настраивать новые сервера для работы, применяя тот или иной сервисный профиль (Service Profile).
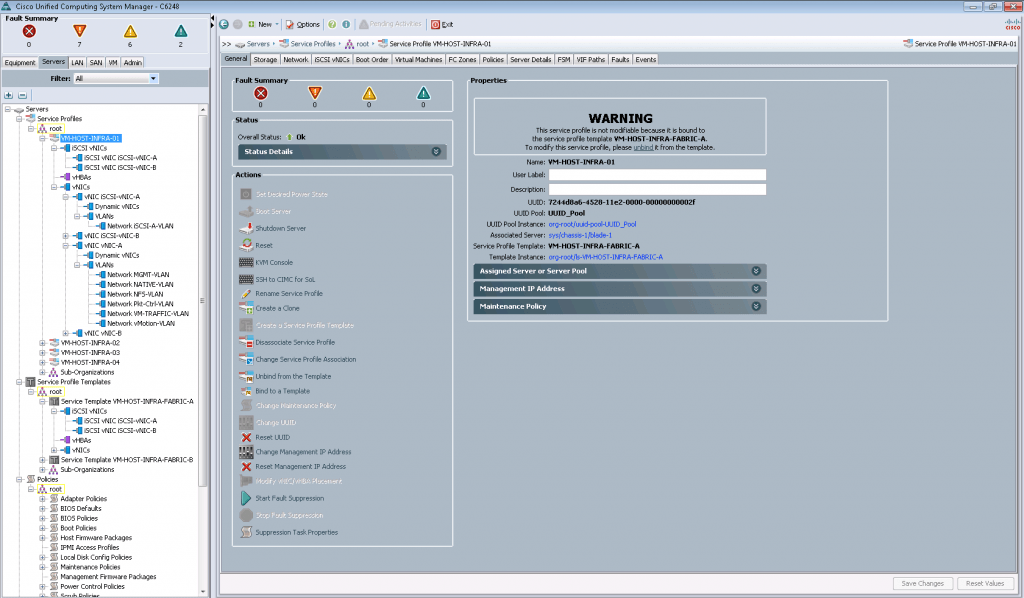
Сервисный профиль, который содержит в себе вышеупомянутые настройки, может быть применен к одному определенному серверу, либо группе серверов. Если в ходе развертывания возникают какие-либо ошибки или сообщения – мы можем посмотреть их в соответствующей вкладке «Faults»:
После чего пользователи этих организаций могут развернуть и настроить сервер под себя с выбранной операционной системой и набором предустановленным набором программного обеспечения. Для этого необходимо воспользоваться возможностями интерфейса UCS Manager, либо обратившись к автоматизации: например при помощи продукта VMware vCloud Automation Center или Cisco Cloupia.
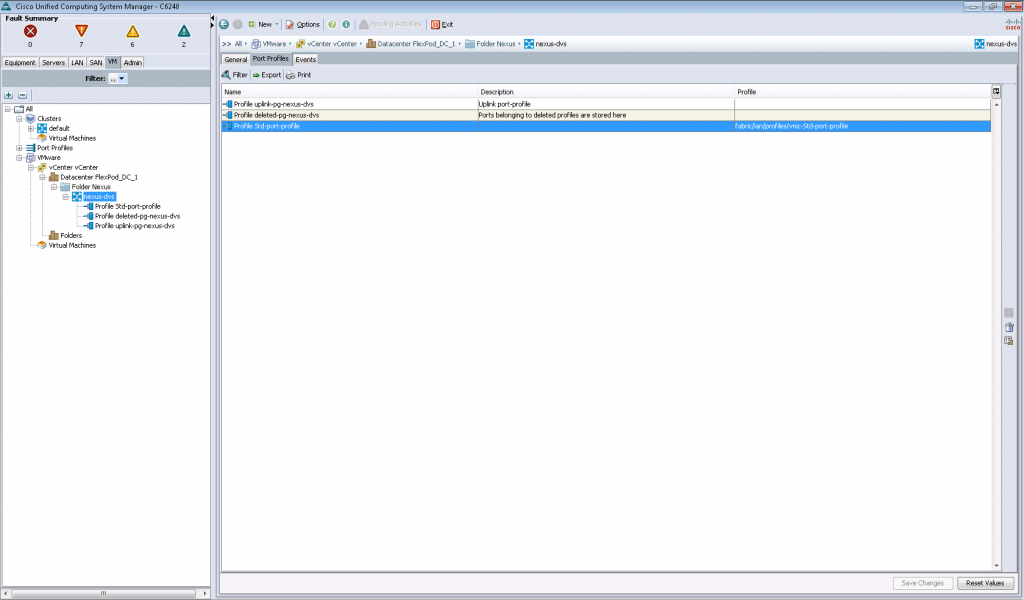
Переходим на вкладку «VM».
В VMware vCenter можно установить плагины для Cisco UCS Manager. Так, мы подключили плагин, через который подключили виртуальный дата-центр с названием «FlexPod_DC_1». В нем работает Cisco Nexus 1000v (nexus-dvs), и мы имеем возможность смотреть его настройки.
Ну и последняя вкладка: «Admin».
Здесь мы можем посмотреть глобальные события: ошибки, предупреждения. Собрать различные данные в случае обращения в поддержку Cisco TAC и т.п. вещи. В частности их можно получить на вкладках «TechSupport Files», «Core Files».
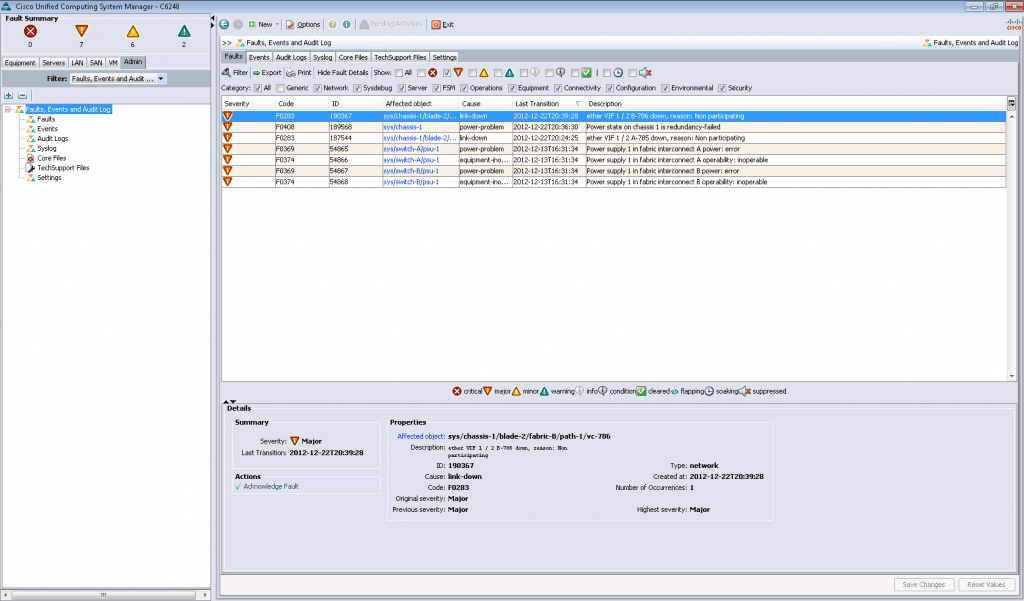
На скриншоте видны ошибки, связанные с отключением электричества. В рамках тестирования мы отключали по очереди блоки питания (Power supply 1 in fabric interconnect A, B) для демонстрации заказчику стабильности работы системы при смоделированном случае отключения подачи питания на одном энерговводе.
В качестве заключения хотим отметить, что весь процесс настройки и тестирования FlexPod, частью которого является настройка и тест Cisco UCS, занял целую неделю. Немного усложнило задачу отсутствие документации для последней версии UCS Manager 2.1. Приходилось пользоваться вариантом для 2.0, который имеет ряд расхождений. На всякий случай выкладываем ссылку на документацию. Возможно, и она кому-нибудь пригодится.
В следующих постах мы продолжим освещать тему FlexPod. В частности мы планируем рассказать о том, как мы вместе с заказчиком тестировали NetApp в режиме MetroCluster в составе FlexPod. Не отключайтесь!


