Что такое инференс ИИ и как это работает?
Инференс в машинном обучении (от англ. inference — логический вывод) — это применение обученной модели для получения предсказаний на новых данных. Тренировка модели аналогична процессу обучения, где модель настраивается на датасетах, а инференс — это этап применения знаний для обработки реальных входных данных.
Инференс больше, чем просто воспроизведение заученного. Модель обобщает закономерности, полученные во время обучения, и применяет их к новым данным. В производственных системах инференс обеспечивает анализ данных с датчиков, обработку запросов в реальном времени и прогнозирование событий.
Особенности инференса
Инференс нейронных сетей обладает рядом характерных особенностей:
- Статичность архитектуры. После завершения обучения структура модели и её веса остаются неизменными. Система применяет усвоенные закономерности без дальнейшей модификации параметров.
- Работа с живыми данными. Модель обрабатывает информацию из реальных источников: видеопотоки с камер, текстовые запросы пользователей, показания датчиков промышленного оборудования. Эти данные могут отличаться от тренировочных по формату, качеству или распределению.
- Требования к производительности. Скорость инференса критична для большинства применений. Автопилот должен распознавать препятствия за миллисекунды, чат-бот — отвечать без заметных задержек, система видеонаблюдения — анализировать потоки с сотен камер одновременно.
- Ограниченные ресурсы. В отличие от обучения, которое обычно проводится на мощных серверах, инференс часто выполняется на устройствах с ограниченной вычислительной мощностью, таких как смартфоны, встроенные системы, граничные устройства IoT.
Модель может показывать впечатляющую точность на тестовых данных, но если инференс занимает несколько секунд или требует дорогостоящего оборудования, система окажется непригодной для реального использования.
Чем отличается инференс LLM от обучения LLM?
Обучение и инференс больших языковых моделей решают разные задачи и требуют различных подходов к организации вычислений.
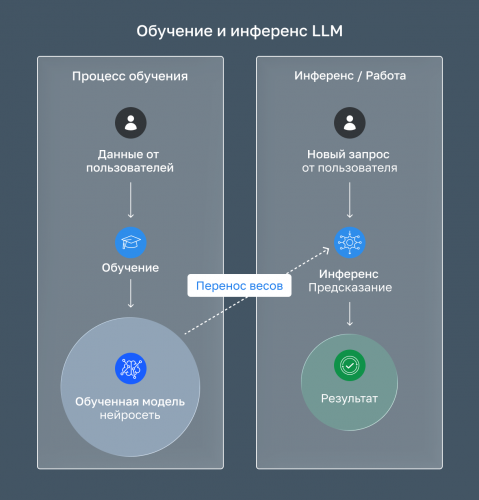
Рис. 1 — Обучение и инференс LLM
Обучение LLM — процесс настройки параметров модели на огромных объёмах текстовых данных. Модель учится предсказывать следующее слово, анализируя миллиарды примеров, корректируя веса нейронной сети через многократные проходы по датасету. Обучение крупных моделей вроде GPT-4 или DeepSeek-V3 требует кластеров из тысяч GPU и может длиться недели или месяцы.
Инференс LLM — использование уже обученной модели для генерации ответов на запросы пользователей. Когда вы задаёте вопрос ChatGPT или используете Llama для генерации текста, модель обрабатывает ваш промпт и создаёт ответ на основе зафиксированных параметров. Модель больше не учится — она применяет усвоенные знания.
Вот как различаются эти процессы:
| Критерий | Обучение LLM | Инференс LLM |
| Что происходит | Настройка миллиардов параметров на датасете | Генерация ответов на основе промптов пользователей |
| Изменение модели | Параметры постоянно обновляются | Параметры зафиксированы и не меняются |
| Длительность | Недели или месяцы непрерывных вычислений | Секунды на один запрос |
| Частота | Выполняется один раз или периодически | Выполняется с каждым запросом пользователя |
| Оборудование | Кластеры из сотен или тысяч GPU | Можно запустить на одном GPU или CPU |
| Объём данных | Петабайты текста, триллионы токенов | Один промпт (от нескольких слов до страниц) |
| Тип затрат | Капитальные (единоразовые инвестиции) | Операционные (расходы на каждый запрос) |
Табл. 1 — Чем отличается обучение LLM от инференса
Что такое инференс LLM с точки зрения бизнеса? Это момент, когда модель начинает «работать» и приносить пользу: чат-боты отвечают клиентам, помощники пишут код, системы переводят документы.
Модель обучают один раз, но инференс выполняется миллионы раз ежедневно. Именно поэтому компании так озабочены оптимизацией инференса. Даже небольшое ускорение или снижение стоимости одного запроса превращается в значительную экономию при массовом использовании.
Где применяется инференс?
Инференс ИИ стал незаметной, но важной частью цифровой инфраструктуры. Технология работает повсеместно, часто оставаясь невидимой для конечного пользователя.
Обработка естественного языка
Корпоративные чат-боты обрабатывают обращения клиентов, отвечая на типовые вопросы и передавая сложные случаи операторам. Системы машинного перевода переводят сообщения, документы и веб-страницы на десятки языков.
Компьютерное зрение
Камеры видеонаблюдения в торговых центрах и на улицах анализируют поведение посетителей, выявляют подозрительную активность и правонарушения, отслеживают количество людей в помещении. Медицинские системы анализируют рентгеновские снимки, КТ и МРТ, помогают врачам обнаруживать патологии на ранних стадиях. Дроны анализируют состояние сельскохозяйственных земель и оценивают урожай.
Рекомендательные системы
Стриминговые сервисы анализируют историю просмотров и предлагают фильмы и сериалы, которые могут заинтересовать конкретного пользователя. Маркетплейсы показывают товары на основе предпочтений покупателя, его корзины и поведения похожих пользователей. Музыкальные платформы составляют персональные плейлисты, учитывают время суток, настроение и контекст прослушивания.
Финансовый сектор
Антифрод-системы анализируют транзакции в режиме реального времени, выявляя подозрительные операции за миллисекунды до их завершения. Алгоритмические торговые системы обрабатывают потоки рыночных данных и принимают решения о покупке или продаже активов быстрее, чем это может сделать человек. Скоринговые модели оценивают кредитоспособность заёмщиков, анализируя десятки параметров за секунды.
Промышленность и производство
Системы предиктивного обслуживания анализируют данные с датчиков оборудования и предсказывают поломки за несколько дней до их возникновения. Компьютерное зрение на конвейерах выявляет дефекты и брак продукции, которые человеческий глаз может пропустить. Роботы на складах распознают объекты, планируют траектории движения и координируют действия между собой без участия операторов.
Здравоохранение
Системы диагностики анализируют биомаркеры и лабораторные показатели, помогая врачам ставить диагнозы. Носимые устройства мониторят показатели здоровья в режиме реального времени, предупреждая о потенциальных проблемах. Модели прогнозирования помогают планировать загрузку больниц и распределять ресурсы.
Локальный инференс набирает популярность в приложениях, где критична конфиденциальность или нет стабильного подключения к интернету. Смартфоны выполняют распознавание лиц и обработку фотографий без отправки данных в облако. Промышленное оборудование принимает решения на месте, не дожидаясь ответа от удалённых серверов.
Как работает инференс?
Инференс языковой модели — это процесс превращения входного промпта в готовый ответ. Всё происходит строго последовательно, токен за токеном, с использованием зафиксированных весов модели.
Этап 1. Получение запроса
Пользователь отправляет промпт, то есть текстовый запрос на естественном языке, например «Какие GPU подходят для запуска языковых моделей?».
Этап 2. Разбивка на токены
Модель не работает с текстом напрямую. Она разбивает входное сообщение на токены — небольшие фрагменты: слова, части слов или символы:[«Как», «ие», «GPU», «под», «ход», «ят», «для», «запу», «ска», «язы», «ковых», «мод», «елей», «?»]. Каждый токен получает числовой идентификатор из словаря модели.
Этап 3. Загрузка токенов в контекстное окно
Все токены (системный промпт + история диалога + текущий запрос) помещаются в контекстное окно (ограниченный объём памяти модели). Размер окна фиксирован: у разных моделей это может быть 4k, 8k, 32k, 128k токенов и больше. Всё, что не поместилось, модель просто не видит.
Важно: чем длиннее контекст, тем медленнее работает модель. Если удвоить длину контекста, каждый шаг генерации займет примерно в 4 раза больше времени.
Этап 4. Поэтапная авторегрессивная генерация ответа
Модель создаёт ответ не целиком, а по одному токену за раз:
- На первом шаге видит только входные токены → предсказывает самый вероятный следующий токен.
- Добавляет только что сгенерированный токен к контексту → предсказывает следующий.
И так далее, пока не будет достигнут специальный токен конца последовательности () или лимит длины. На этом этапе влияют два параметра генерации:
- Температура — управляет случайностью. Низкая (0.1–0.4) даёт предсказуемые и точные ответы. Высокая (0.8–1.2) повышает креативность, но может снижать связность.
- Ограничение длины (max tokens) — ограничивает максимальное количество токенов в ответе и защищает от бесконечной генерации.
Этап 5. Формирование и отдача финального ответа
Как только выполнено одно из условий остановки, последовательность токенов превращается обратно в читаемый текст и отправляется пользователю. Ответ может прийти целиком или потоково, токен за токеном в реальном времени.
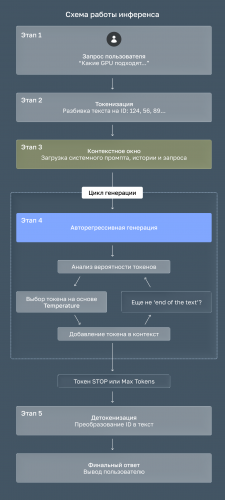
Рис. 2 — Схема работы инференса
Из-за авторегрессивной природы генерации каждый новый токен требует нового прохода через всю модель. Длинный контекст и высокая температура ощутимо увеличивают время и стоимость инференса.
Факторы, которые влияют на скорость и стоимость инференса
Производительность инференса определяет, насколько быстро пользователь получит ответ и во сколько это обойдётся бизнесу. Скорость инференса зависит от комбинации аппаратных, программных и архитектурных решений.
| Фактор | На что влияет | Как оптимизировать |
| Размер модели | Время ответа, память | Квантование, дистилляция |
| Длина промпта | Задержка | Сжатие контекста |
| Тип GPU | Пропускная способность | Выбор H100/A100 |
| Батчинг | Пропускная способность | Continuous batching |
| Количество GPU | Масштаб | Tensor / pipeline parallelism |
Табл. 2 — Факторы влияющие на скорость и стоимость инференса
Выбор вычислительного оборудования напрямую влияет на скорость обработки запросов. Центральные процессоры (CPU) подходят для небольших моделей, но плохо справляются с матричными вычислениями. Графические процессоры (GPU) содержат тысячи ядер и обрабатывают множество операций одновременно. Тензорные процессоры (TPU и NPU) заточены специально под нейросетевые вычисления и работают энергоэффективнее.
Количество параметров определяет объём вычислений для каждого запроса. Модель на 70 миллиардов параметров требует в десятки раз больше операций, чем модель на 7 миллиардов. Все параметры нужно загрузить в оперативную память, поэтому модель на 175 миллиардов параметров занимает около 350 ГБ. Пропускная способность памяти часто становится узким местом.
Размер входных данных напрямую влияет на время обработки. Механизм внимания в трансформерах работает так, что каждый токен должен «посмотреть» на все остальные токены в контексте. Из-за этого вычислительная сложность растёт квадратично. Если удвоить длину промпта, время обработки увеличится примерно в четыре раза. Длина генерируемого ответа тоже важна, потому что модель создаёт текст токен за токеном.
Место размещения инфраструктуры влияет на задержки и доступность сервиса. Облачные вычисления дают доступ к мощному оборудованию по требованию и позволяют запускать модели ближе к пользователям. Локальный инференс выполняется на конечном устройстве без отправки данных в облако, это снижает задержки и нейтрализует зависимость от интернета. Гибридные решения комбинируют оба подхода.
Количество одновременных запросов определяет, насколько эффективно используются вычислительные ресурсы. Пакетная обработка объединяет несколько запросов и обрабатывает их вместе, потому что GPU эффективнее работает с батчами. Параллелизация на нескольких GPU распределяет модель между ускорителями, это необходимо для очень больших моделей. Непрерывная пакетная обработка динамически группирует запросы без ожидания фиксированного размера батча.
Как оптимизировать и ускорить инференс?
Ускорение инференса позволяет снизить затраты на вычисления и улучшить пользовательский опыт. Рассмотрим проверенные методы оптимизации, которые можно применить последовательно или комбинировать для максимального эффекта.
Шаг 1. Применить квантование модели
Квантование снижает точность представления параметров модели с 32-битных чисел с плавающей точкой до 16-битных или 8-битных целых чисел. Размер модели уменьшается в 2-4 раза, а вычисления ускоряются, потому что целочисленные операции выполняются быстрее операций с плавающей точкой. Например, модель на 70 миллиардов параметров в формате FP32 занимает 280 ГБ памяти, а после квантования в INT8 всего 70 ГБ. Современные методы квантования сохраняют качество ответов на уровне 95-98% от исходной модели.
Шаг 2. Оптимизировать архитектуру через обрезку или дистилляцию
Обрезка удаляет наименее значимые параметры или слои из модели без заметной потери качества. Дистилляция знаний переносит способности большой модели в компактную версию. «Учительская» модель обучает «студенческую», передавая ей паттерны принятия решений. Модель на 175 миллиардов параметров можно сжать до 13 миллиардов с сохранением 90% производительности.
Шаг 3. Настроить пакетную обработку запросов
Пакетная обработка объединяет несколько запросов и обрабатывает их одновременно. Утилизация GPU повышается с 30-40% до 80-90%. Непрерывная пакетная обработка динамически формирует батчи без ожидания фиксированного количества запросов. Система начинает обработку сразу и добавляет новые запросы в текущий батч. Правильная настройка размера батча позволяет обрабатывать в 5-10 раз больше запросов в секунду на том же оборудовании.
Шаг 4. Внедрить кэширование и переиспользование вычислений
Кэширование промежуточных результатов избавляет от повторных вычислений при обработке похожих запросов. Управление кэшем KV сохраняет результаты механизма внимания для общих частей промптов. Если несколько пользователей задают вопросы с одинаковым системным промптом, модель вычисляет его только один раз. Спекулятивное декодирование использует меньшую черновую модель для предсказания нескольких токенов вперёд, которые затем проверяет основная модель. Ускорение генерации на 30-50% при сохранении качества.
Шаг 5. Распределить нагрузку на несколько ускорителей
Параллелизация на нескольких GPU позволяет обрабатывать большие модели и увеличивать пропускную способность. Тензорный параллелизм разделяет слои модели между устройствами, конвейерный распределяет последовательные блоки, параллелизм по данным реплицирует модель на несколько GPU для одновременной обработки разных запросов. Высокоскоростные интерконнекты вроде NVLink или InfiniBand минимизируют задержки при передаче данных между ускорителями. Решение необходимо для моделей более 100 миллиардов параметров, которые не помещаются в память одного GPU.
Где проводить инференс?
Выбор места развертывания инфраструктуры для инференса влияет на скорость, стоимость и гибкость решения. Рассмотрим три основных варианта и их особенности.
Собственная инфраструктура (on-premise)
Стоимость реализации высокая — от 300 000 $ за сервер с 8× NVIDIA H100, плюс расходы на строительство серверной, системы охлаждения и ИБП. Время развертывания занимает 2-6 месяцев с учетом сроков поставки оборудования, доставки, установки и настройки. Масштабирование требует закупки нового оборудования и расширения мощности дата-центра. Производительность максимальная при выделенном железе и оптимизации под конкретные задачи. Контроль и безопасность зависят от внутренних мер компании, включая отказоустойчивость (например, резервное питание и дублирование систем). Подходит для проектов с постоянной высокой нагрузкой, где важны строгие требования к данным и есть команда для поддержки инфраструктуры.
Аренда выделенного сервера
Стоимость реализации отсутствует в виде капитальных затрат — платите только за аренду. Время развертывания 1-3 дня, провайдер предоставляет готовый настроенный сервер. Масштабирование средней скорости — аренда дополнительных серверов за 1-3 дня с миграцией. Производительность максимальная, выделенный сервер без соседей обеспечивает предсказуемую работу. Контроль и безопасность высокий: физическая изоляция сервера, данные в дата-центре провайдера, SLA и гарантированная отказоустойчивость. Подходит для проектов со стабильной нагрузкой, где нужна предсказуемая производительность без капитальных затрат и есть возможность миграции.
Облачная инфраструктура
Стоимость реализации отсутствует — платите за использование. Время развертывания пару часов на запуск виртуальной машины с GPU. Масштабирование автоматическое добавление ресурсов за минуты. Производительность высокая при правильной конфигурации, возможны колебания при общих ресурсах, но можно реализовать в частном контуре для изоляции. Контроль и безопасность зависят от провайдера: изолированные сети, шифрование, compliance-сертификаты, SLA и гарантированная отказоустойчивость. Подходит для проектов с переменной нагрузкой, экспериментов с моделями, сезонных сервисов и быстрого масштабирования, где важна гибкость и отсутствие капитальных инвестиций.
Для большинства компаний, особенно на начальных этапах внедрения ИИ, облачная инфраструктура или аренда сервера оказываются оптимальным выбором по соотношению затрат, скорости развертывания и гибкости. Собственная инфраструктура имеет смысл только при постоянной высокой нагрузке и возможности инвестировать миллионы в оборудование и персонал.
Облачная инфраструктура ITGLOBAL.COM для инференса
ITGLOBAL.COM предоставляет облачную инфраструктуру, специально оптимизированную под задачи инференса ИИ и больших языковых моделей. Решение развернуто в дата-центрах Tier III в десяти странах мира, что позволяет запускать модели ближе к конечным пользователям и минимизировать задержки.
Оптимизированное оборудование
Инфраструктура построена на серверах с графическими ускорителями NVIDIA последних поколений — A100, H100 и L40S. Серверы оснащены процессорами Intel Xeon Gold с высокой тактовой частотой и большими объемами оперативной памяти DDR5, что критично для быстрой загрузки моделей. Высокоскоростные SSD-накопители NVMe обеспечивают мгновенный доступ к параметрам модели, а сетевые адаптеры с поддержкой RDMA минимизируют задержки при распределенном инференсе на нескольких GPU.
Гибкость и масштабирование
Облачная платформа позволяет запускать модели любого размера. Автоматическое масштабирование подстраивает количество вычислительных ресурсов под текущую нагрузку. В периоды пиковой активности система добавляет GPU, в периоды спада освобождает их. Вы платите только за фактически использованное время работы ускорителей, поминутная тарификация исключает переплату за простаивающие мощности.
Техническая поддержка и сервис
Команда ITGLOBAL.COM оказывает техническую поддержку 24/7 с временем реакции 15 минут. Специалисты помогают подобрать оптимальную конфигурацию под конкретную модель, настроить инфраструктуру для максимальной производительности, решить возникающие технические вопросы. Мониторинг инфраструктуры работает круглосуточно. Система автоматически отслеживает состояние оборудования и переносит нагрузку на резервные ресурсы при возникновении сбоев.
Начало работы
Запуск инференса в облаке ITGLOBAL.COM занимает минуты. Выберите конфигурацию GPU через веб-интерфейс, разверните виртуальную машину, загрузите модель и начинайте обрабатывать запросы. Доступны готовые образы с предустановленными фреймворками для инференса: vLLM, TensorRT-LLM, Hugging Face TGI. Тестовый период позволяет оценить производительность инфраструктуры на реальных задачах перед принятием решения о долгосрочном использовании.
Заключение
Инференс ИИ и LLM — ключевой этап применения моделей, где обученная система генерирует предсказания на новых данных без изменения параметров, в отличие от обучения, требующего масштабных вычислений и обновления весов. Оптимизация инференса через квантование, дистилляцию, пакетную обработку и распределение нагрузки позволяет ускорить процесс в 5-10 раз, снизив операционные затраты. Выбор инфраструктуры — on-premise, выделенный сервер или облако — зависит от нагрузки, бюджета и требований к безопасности: облачные решения обеспечивают гибкость и быстрое масштабирование, выделенные — предсказуемую производительность, а собственная инфраструктура — полный контроль при высоких инвестициях. Правильный подход к инференсу делает ИИ-проекты рентабельными и эффективными в производственной среде.
FAQ
Что такое инференс в машинном обучении простыми словами?
Инференс в машинном обучении — это применение обученной модели для получения предсказаний на новых данных. Если обучение модели похоже на учёбу студента перед экзаменом, то инференс — это сам экзамен, где модель демонстрирует усвоенные знания на практике. Например, когда вы задаёте вопрос ChatGPT или смартфон распознаёт ваше лицо для разблокировки — это инференс.
Чем инференс LLM отличается от обучения LLM?
Обучение LLM — это процесс настройки миллиардов параметров модели на огромных объёмах текста, который может длиться недели или месяцы на кластерах из тысяч GPU. Инференс LLM — это использование уже обученной модели для генерации ответов на запросы пользователей за секунды. Модель обучают один раз, но инференс выполняется миллионы раз ежедневно, поэтому его оптимизация критична для снижения операционных затрат.
Что влияет на скорость инференса нейронных сетей?
Скорость инференса зависит от типа вычислительного оборудования (CPU, GPU, TPU), размера модели и количества параметров, длины входного промпта и генерируемого ответа, места размещения инфраструктуры (облако, выделенный сервер, собственное оборудование) и способа обработки запросов (последовательно или пакетами). Модель на 70 миллиардов параметров с промптом на 10 000 токенов обрабатывается значительно дольше, чем модель на 7 миллиардов с промптом на 100 токенов.
Как ускорить инференс модели?
Ускорение инференса достигается через квантование модели (снижение точности с FP32 до INT8), оптимизацию архитектуры через обрезку или дистилляцию, настройку пакетной обработки запросов, внедрение кэширования промежуточных результатов и распределение нагрузки на несколько GPU. Комбинация этих методов может ускорить инференс в 5-10 раз при сохранении качества ответов на уровне 95-98% от исходной модели.
Что такое локальный инференс и когда его использовать?
Локальный инференс — это выполнение модели непосредственно на конечном устройстве пользователя (смартфоне, ноутбуке, встроенной системе) без отправки данных в облако. Его используют, когда критична конфиденциальность данных, нет стабильного подключения к интернету или важна минимальная задержка ответа. Например, распознавание лиц в смартфоне происходит локально, чтобы биометрические данные не покидали устройство.
Где лучше запускать инференс — в облаке или на собственном оборудовании?
Для большинства компаний облако или аренда сервера оптимальны по соотношению затрат, скорости развертывания и гибкости. Облако позволяет начать работу за минуты, масштабироваться автоматически и платить только за использование. Собственная инфраструктура оправдана только при постоянной высокой нагрузке и готовности инвестировать от 300 000 долларов в оборудование плюс расходы на дата-центр и персонал.
Что такое режим инференса в контексте больших языковых моделей?
Режим инференса определяет способ обработки запросов и генерации ответов. Потоковая генерация отправляет токены пользователю сразу по мере создания — текст появляется постепенно, как в ChatGPT. Пакетная обработка накапливает несколько запросов и обрабатывает их вместе для повышения утилизации GPU. Выбор режима зависит от требований к задержке и пропускной способности системы.
Сколько стоит инференс больших языковых моделей?
Стоимость зависит от размера модели, длины промпта и ответа, типа оборудования и места размещения. В облаке час работы GPU NVIDIA A100 стоит 1-3 доллара, H100 — 3-5 долларов. Для модели на 70 миллиардов параметров один запрос может стоить от долей цента до нескольких центов. При обработке миллионов запросов в день расходы составляют тысячи долларов в месяц, поэтому оптимизация инференса критична для рентабельности проекта.

